Caractères génériques Windows et expressions régulières Windows
Caractères génériques Windows vous permet de spécifier un fichier ou un groupe de fichiers en tapant un nom de fichier partiel. Le répertoire approprié est analysé pour trouver tous les fichiers correspondant au nom partiel. Vous pouvez aussi utiliser expressions régulières pour spécifier des fichiers lors de l'utilisation TCC (voir ci-dessous).
Les caractères génériques sont généralement utilisés pour spécifier quels fichiers devrait être traité par une commande. Si vous devez spécifier quels fichiers doivent ne sauraient être traité, voir Plages d'exclusion de fichiers (Pour TCC commandes internes), ou SAUF (pour les commandes externes).
La plupart des commandes internes dans TCC ou CMD accepte les noms de fichiers avec des caractères génériques partout où un nom de fichier complet peut être utilisé. Il y a deux caractères génériques, l'astérisque * et le point d'interrogation ?. De plus, dans TCC vous pouvez spécifier un jeu de caractères (voir ci-dessous).
AVERTISSEMENT: Lorsque vous utilisez une recherche générique pour les fichiers à traiter dans une commande telle que POUR or DO, et que vous créez de nouveaux noms de fichiers (que ce soit en renommant des fichiers existants ou en créant de nouveaux fichiers), les nouveaux noms de fichiers peuvent correspondre au caractère générique de votre sélection et vous obliger à les traiter à nouveau.
Astérisque * caractère générique
An astérisque * dans une spécification de fichier, cela signifie "un ensemble de caractères quelconques ou aucun caractère à cette position". Par exemple, la commande suivante affichera une liste de tous les fichiers (y compris les répertoires, mais excluant les fichiers et répertoires avec au moins un des attributs caché ainsi que les combustion propre) dans le répertoire courant :
rép *
Si vous souhaitez voir tous les fichiers avec un .TXT extension:
dir * .txt
Si vous savez que le fichier que vous recherchez a un nom de base qui commence par ST et une extension qui commence par .D, vous pouvez le trouver de cette façon. Les noms de fichiers tels que ETAT.DAT, STEVEN.DOC, ainsi que les ST.D seront tous affichés :
dir st*.d*
TCC vous permet également d'utiliser l'astérisque pour faire correspondre les noms de fichiers avec des lettres spécifiques quelque part dans le nom. L'exemple suivant affichera n'importe quel fichier avec un .TXT extension qui a les lettres AM ensemble n'importe où à l'intérieur de son nom de base. Il affichera par exemple AMPLE.TXT, TIMBRE.TXT, CLAM.TXTet la AM.TXT, mais il ignorera RÉCLAMATION.TXT:
répertoire *am*.txt
Point d'interrogation ? caractère générique
A point d'interrogation ? correspond à n’importe quel caractère du nom de fichier. Vous pouvez placer le point d'interrogation n'importe où dans un nom de fichier et utiliser autant de points d'interrogation que nécessaire. L'exemple suivant affichera des fichiers avec des noms comme LETTRE.DOC, DERNIER.DAT, ainsi que les LITTER.DU:
dir l?tter.d??
L'utilisation d'un caractère générique astérisque avant d'autres caractères et des plages de caractères décrites ci-dessous constituent des améliorations de la syntaxe standard des caractères génériques Microsoft et ne fonctionneront probablement pas correctement avec des logiciels autres que TCC.
Les points d'interrogation "supplémentaires" dans votre spécification générique sont ignorés si le nom de fichier est plus court que la spécification générique. Par exemple, si vous avez des fichiers appelés LETTRE.DOC, LETTRE1.DOCet la LETTRE.DOC, cette commande affichera les trois noms :
lettre dir?.doc
Le fichier LETTRE.DOC est inclus dans l'affichage car le point d'interrogation "extra" à la fin de LETTRE? est ignoré lors de la correspondance avec le nom le plus court LETTRE.
Caractères génériques de jeu de caractères
Dans certains cas, ? le caractère générique est peut-être trop général. TCC (mais pas CMD) vous permet également de spécifier l'ensemble exact des caractères que vous souhaitez accepter (ou exclure) à une position particulière dans le nom de fichier en utilisant des crochets []. À l’intérieur des parenthèses, vous pouvez mettre les caractères individuels acceptables ou les plages de caractères. Par exemple, si vous vouliez faire correspondre LETTRE0.DOC à travers LETTRE9.DOC, vous pouvez utiliser cette commande :
dir lettre[0-9].doc
Vous pouvez ainsi trouver tous les fichiers dont le nom contient une voyelle comme deuxième lettre. Cet exemple montre également comment mélanger les caractères génériques :
dir ?[aeiouy]*
Vous pouvez exclure un groupe de caractères ou une plage de caractères en utilisant un point d'exclamation [!] comme premier caractère entre parenthèses. Cet exemple affiche tous les noms de fichiers comportant au moins 2 caractères, à l'exception de ceux dont la deuxième lettre est une voyelle :
dir ?[!aeiouy]*
L'exemple suivant, qui sélectionne des fichiers tels que AIP, BIPet la ASTUCE mais pas PIN, montre comment vous pouvez utiliser plusieurs plages entre crochets. Il acceptera un fichier commençant par un A, B, C, D, T, Uou V:
rép [a-dt-v]ip
Vous pouvez utiliser un point d'interrogation entre crochets, mais sa signification est légèrement différente d'un caractère générique de point d'interrogation normal (sans crochets). Un caractère générique de point d'interrogation normal correspond à n'importe quel caractère, mais sera ignoré lors de la correspondance avec un nom plus court que la spécification du caractère générique, comme décrit ci-dessus. Un point d'interrogation entre parenthèses correspondra à n'importe quel caractère, mais ne sauraient être ignoré lors de la correspondance avec des noms de fichiers plus courts. Par exemple:
dir lettre[?].doc
Affichera LETTRE1.DOC ainsi que les LETTRE.DOC, Mais pas LETTRE.DOC.
Vous pouvez répéter n'importe lequel des caractères génériques dans n'importe quelle combinaison souhaitée dans un seul nom de fichier. Par exemple, la commande suivante répertorie tous les fichiers qui ont un A, Bou C comme troisième caractère, suivi de zéro ou plusieurs caractères supplémentaires, suivis d'un D, Eou F, suivi éventuellement de quelques caractères supplémentaires, et d'une extension commençant par P or Q. Vous n'aurez probablement pas besoin de faire quelque chose d'aussi complexe, mais nous l'avons inclus pour vous montrer la flexibilité des caractères génériques étendus :
rép ??[abc]*[def]*.[pq]*
Vous pouvez également utiliser la syntaxe des caractères génériques entre crochets pour contourner un conflit entre des noms de fichiers longs contenant des points-virgules [;], et l'utilisation d'un point-virgule pour indiquer un inclure la liste. Par exemple, si vous avez un fichier sur un lecteur LFN nommé C:\DONNÉES\LETTRE1;V2 et tu tapes cette commande :
del \data\letter1;v2
vous n'obtiendrez pas les résultats escomptés. Au lieu de supprimer le fichier nommé, TCC va tenter de supprimer LETTRE1 et alors V2, car le point-virgule indique un inclure la liste. Cependant, si vous utilisez des crochets autour du point-virgule, celui-ci sera interprété comme un caractère de nom de fichier et non comme un séparateur de liste d'inclusion. Par exemple, cette commande supprimerait le fichier nommé ci-dessus :
del \data\letter1[;]v2
Correspondance des noms de fichiers courts (SFN)
Si l'option de configuration Rechercher les SFN est définie, dans TCC Les recherches par caractères génériques acceptent une correspondance soit sur le LFN or le SFN pour correspondre au comportement de CMD. Cela peut entraîner la recherche de certains fichiers uniquement en raison d'une correspondance SFN. Dans la plupart des situations, cela n'est pas réellement souhaitable et peut être évité en désactivant l'option (le défaut).
Remarque: Le joker le processus d'expansion tentera de permettre à la fois CMD-style "extension" correspondant (une seule extension, à la fin du mot) et avancé TCC correspondance de nom de fichier (permettant des choses comme *.*.abc) lorsqu'un astérisque est rencontré dans la destination d'un COPY, MOVE or REN / RENOMMER commander.
Caractères génériques dans les noms de répertoires
TCC (mais pas CMD) prend en charge les caractères génériques dans les noms de répertoire (mais pas dans le nom du lecteur), pour les TCC commandes et fonctions. Ces types de caractères génériques sont courants sous Linux, mais ne sont pas pris en charge dans CMD ou dans la plupart des applications Windows.
Vous pouvez contrôler la récursion du sous-répertoire en spécifiant * or ** Sur le chemin. A * correspondra à un seul niveau de sous-répertoire ; un ** correspondra à tous les niveaux de sous-répertoire pour ce nom de chemin. Les caractères génériques de répertoire prennent également en charge les expressions régulières. Les caractères génériques de répertoire ne peuvent pas être utilisés avec l'option /O:... (qui trie les entrées avant d'exécuter la commande). Et réfléchissez bien avant d'utiliser des caractères génériques de répertoire avec une option /S (sous-répertoires récursifs), car cela renverra presque certainement des résultats inattendus !
Par exemple, pour supprimer le fichier Foobar dans n'importe quel sous-répertoire de c:\test\test2 (mais pas dans aucun de leurs sous-répertoires) :
del c:\test\test2\*\foobar
Pour supprimer le fichier Foobar dans n'importe quel sous-répertoire sous c:\test (et tous leurs sous-répertoires) dont le nom contient "foo" :
del c:\test\**\*foo*\foobar
Pour supprimer le fichier Foobar dans n'importe quel sous-répertoire de c:\test commençant par un t et se termine par un 2:
del c:\test\t*2\foobar
Certaines commandes ne prennent pas en charge les caractères génériques de répertoire, car ils seraient dénués de sens ou destructeurs (par exemple, TREE, @FILEOPEN, @FILEDATE, etc.).
Expressions régulières Windows dans TCC
En plus de l'extension Caractères génériques Windows (*, ?, et [...]), TCC soutient l'utilisation de caractères génériques d'expression régulière pour la correspondance et le remplacement du nom de fichier dans les commandes internes de gestion de fichiers (COPY, DEL, DIR, MOVE, REN, etc.). Vous pouvez choisir la syntaxe d'expression régulière que vous souhaitez utiliser - TCC prend en charge les expressions régulières Perl, Ruby, Java, grep, POSIX, gnu, Python et Emacs.
La syntaxe est:
::expression régulière
Par exemple :
rép ::ca[td]
Notez que l'utilisation Expressions régulières Windows ralentira légèrement vos recherches dans l'annuaire : étant donné que Windows ne les prend pas en charge de manière native, le TCC l'analyseur doit convertir le nom du fichier en *, récupérez tous les noms de fichiers, puis faites-les correspondre à l'expression régulière.
Si vous avez des caractères spéciaux (espaces, caractères de redirection, caractères d'échappement, etc.) dans votre expression régulière, vous devrez les mettre entre guillemets. Par exemple:
rép "::^\w{1,8}\.btm$"
Pour plus d'informations sur caractère générique d'expression régulière syntaxe, voir Syntaxe des expressions régulières dans les Take Command aider.
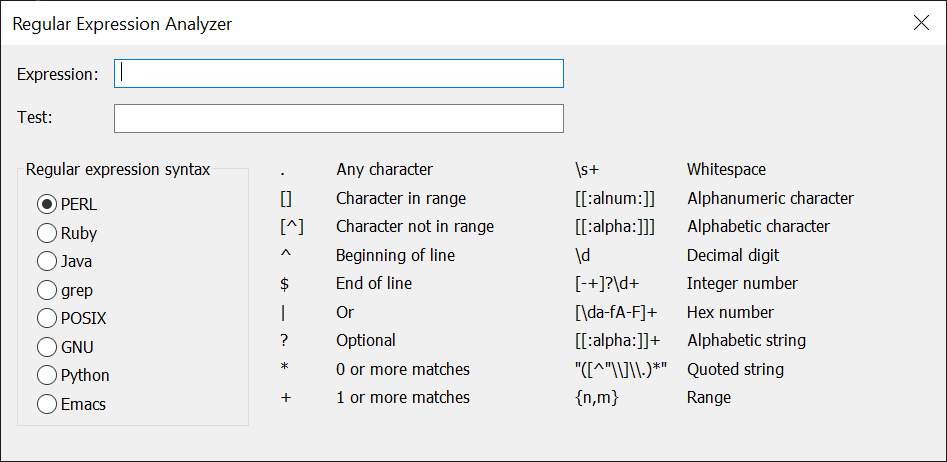
Pour simplifier la création et le test de vos expressions régulières, Take Commande ainsi que les TCC inclure une boîte de dialogue d'analyseur d'expressions régulières (Ctrl-F7 depuis le TCC ligne de commande, ou sous le menu Outils dans Take Command.) Il existe deux zones d'édition :
- La première consiste à tester l'expression régulière. Si l'expression régulière est valide, la boîte de dialogue affichera une coche verte à droite de la zone d'édition de l'expression. Si l'expression régulière n'est pas valide, la boîte de dialogue affichera un X rouge.
- La deuxième zone d'édition concerne le texte que vous souhaitez faire correspondre à l'expression régulière. Si le texte correspond à l'expression régulière, la boîte de dialogue affichera une coche verte à droite de la zone d'édition du test. Si le texte ne correspond pas, la boîte de dialogue affichera un X rouge.